Introduction: Why LLM Integration Is the Fastest ROI in AI
For most businesses, the fastest path to AI-powered value is not building models from scratch — it is integrating existing Large Language Models into products and workflows that already exist. LLM integration services bridge the gap between powerful AI models and your specific business context, transforming generic AI capabilities into features your customers will actually pay for.
Whether you want to add an intelligent search feature to your SaaS platform, automate document processing in your operations, or build a customer-facing AI assistant, the core challenge is the same: how do you make a general-purpose language model behave like a specialist in your domain?
This guide explains exactly how LLM integration works, what the process looks like end-to-end, and how to evaluate whether you need professional AI integration services or can manage it in-house.
What Are LLM Integration Services?
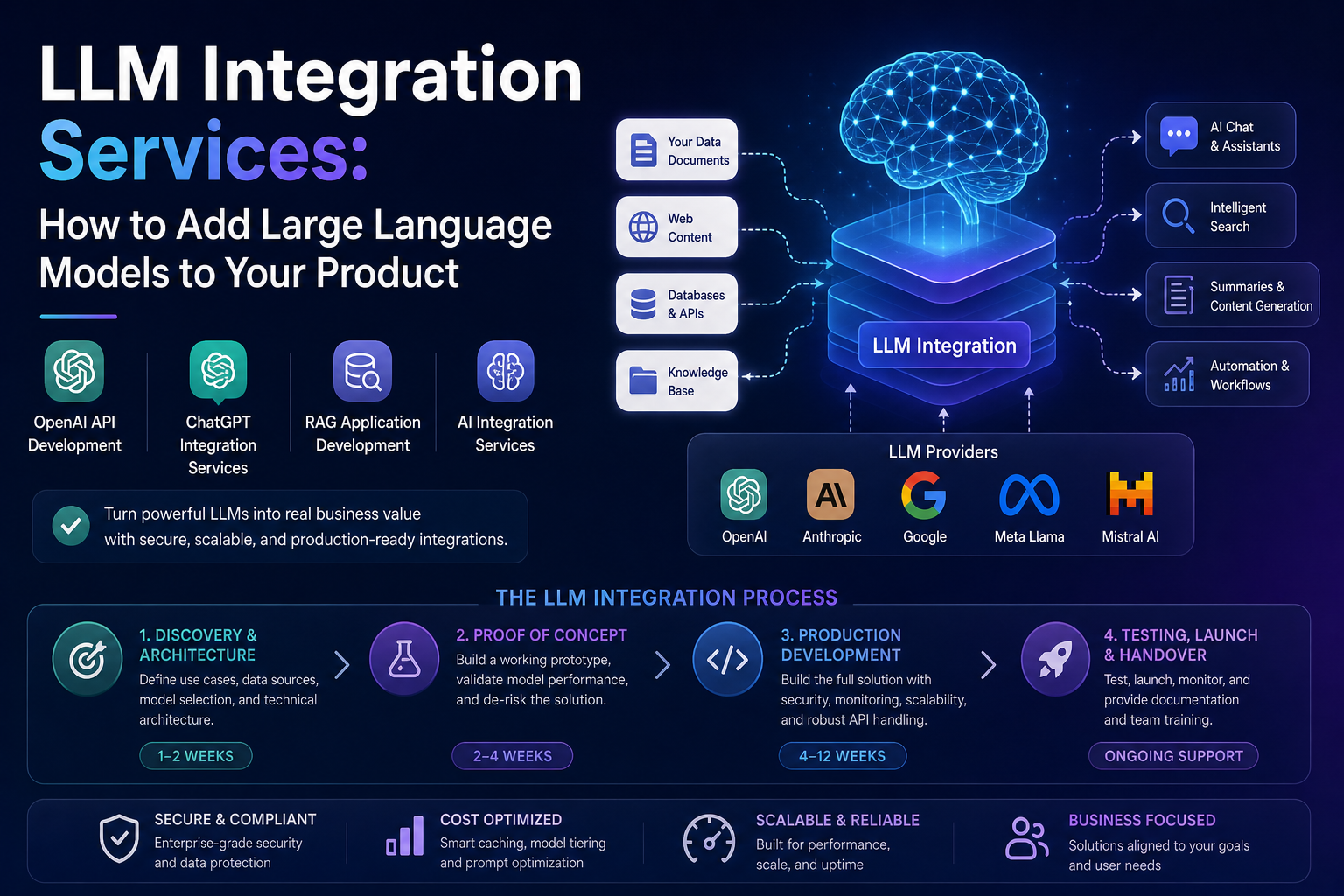
LLM integration services refer to the professional design, engineering, and deployment work required to embed a Large Language Model into a product, platform, or workflow in a way that is reliable, secure, and valuable. This typically includes:
- Selecting the right LLM for your use case (GPT-4, Claude, Gemini, Mistral, Llama, and others)
- Designing the prompting architecture and system instructions that shape model behaviour
- Building the data pipeline that connects your proprietary content to the model (RAG application development)
- Creating the API layer that handles requests, responses, rate limits, and error handling
- Implementing security controls, content moderation, and compliance requirements
- Establishing monitoring, logging, and cost management infrastructure
Done well, LLM integration transforms a generic foundation model into a product feature that feels tailor-made for your users — without the cost and complexity of training a custom model.
The Most Common LLM Integration Patterns
1. Direct API Integration
The simplest form of LLM integration involves calling a model API directly from your application backend. You send a structured prompt and receive a generated response. This pattern suits simple use cases: content generation, summarisation, classification, and basic Q&A.
OpenAI API development and ChatGPT integration services based on this pattern can be delivered rapidly and at relatively low cost. The key engineering challenge is prompt design: crafting system instructions that reliably produce the output format and quality your application requires.
2. Retrieval-Augmented Generation (RAG)
RAG is the dominant integration pattern for knowledge-intensive applications. Instead of relying on the LLM’s training data, you maintain a vector database populated with your organisation’s documents, product information, or knowledge base. At query time, relevant content is retrieved and provided to the model as context.
RAG application development is more complex than direct API integration but delivers dramatically more accurate and trustworthy outputs for domain-specific applications. It also eliminates the hallucination risk that makes naive LLM responses dangerous in professional contexts.
3. Agentic AI Integration
Agentic integrations give the LLM access to tools — web search, database queries, API calls, file operations — allowing it to complete multi-step tasks autonomously. An AI agent integrated into your product can research, draft, review, and submit a document without user intervention at each step.
This is the most powerful and complex integration pattern, requiring careful design of tool permissions, fallback logic, and human oversight checkpoints.
4. Embedded Fine-Tuned Models
For use cases where a fine-tuned model significantly outperforms a prompted general model — typically involving very specific output formats, proprietary terminology, or specialised reasoning — the integration layer connects your application to a fine-tuned model instance rather than a general-purpose API.
How the LLM Integration Process Works
A professional LLM integration engagement typically follows this structure:
Phase 1: Discovery and Architecture Design (1–2 weeks)
The integration team works with your product and business stakeholders to define the use cases, map data sources, select the appropriate model and integration pattern, and produce a technical architecture document. This phase also identifies security and compliance requirements.
Phase 2: Proof of Concept (2–4 weeks)
A working prototype is built for your highest-priority use case, allowing real evaluation of model performance against your specific data and requirements. This phase surfaces prompt engineering challenges, data quality issues, and latency constraints before full development begins.
Phase 3: Production Development (4–12 weeks depending on scope)
The full integration is built to production standards: robust API handling, error recovery, security controls, monitoring, and documentation. If RAG is required, the data pipeline and vector database are built and populated during this phase.
Phase 4: Testing, Launch, and Handover
Integration testing across edge cases, performance testing under realistic load, and user acceptance testing precede launch. A post-launch support period allows rapid response to any production issues, followed by documentation handover and team training.
How Much Do LLM Integration Services Cost?
Cost is determined primarily by the complexity of the integration pattern, the volume and quality of proprietary data to be processed, and the scope of product changes required. Indicative ranges:
- Simple direct API integration (single use case): $8,000–$25,000
- RAG-based knowledge integration: $20,000–$60,000
- Multi-feature AI integration across an existing product: $40,000–$120,000
- End-to-end agentic AI integration: $60,000–$200,000+
Ongoing costs include LLM API usage fees (typically $0.01–$0.06 per 1,000 tokens for leading models), vector database hosting, and monitoring infrastructure. A well-implemented integration will include cost optimisation measures — caching, prompt compression, model tier selection — that keep ongoing expenses manageable.
Choosing the Right LLM for Integration
The leading LLMs available for commercial integration each have distinct strengths:
- GPT-4o (OpenAI): Strong all-round capability, extensive ecosystem, multimodal support
- Claude 3.5 Sonnet/Opus (Anthropic): Exceptional for complex reasoning, long documents, and safety-critical applications
- Gemini 1.5 Pro (Google): Very long context window, strong multimodal performance, Google ecosystem integration
- Llama 3 (Meta): Open-source option for on-premise deployment, no data sharing with third parties
- Mistral / Mixtral: Cost-efficient open-source options for simpler tasks
Model selection should be driven by your specific performance requirements, data sensitivity, latency constraints, and cost targets — not by marketing positioning. A good AI integration services partner will help you benchmark models against your actual use case before committing.
When Should You Use a Professional LLM Integration Service?
In-house integration is viable for teams with strong software engineering capability and a straightforward use case. Professional LLM integration services add the most value when:
- Your use case involves proprietary data that requires RAG or fine-tuning
- You operate in a regulated industry with compliance requirements
- Speed to market is critical and you cannot afford integration failures
- Your team lacks experience with prompt engineering, vector databases, or AI system design
- You need a production-grade, scalable solution rather than a prototype
💡 Looking to integrate an LLM into your product? Our AI integration services team has delivered enterprise-grade LLM integrations across SaaS, healthcare, fintech, and legal sectors. Contact us for a free technical consultation.
Conclusion
LLM integration is the highest-ROI AI investment most businesses can make in 2026. The technology is mature, the APIs are accessible, and the use cases are proven across virtually every industry. The difference between a successful integration and a failed one comes down to architecture, prompt engineering, data quality, and ongoing optimisation.
Whether you tackle integration in-house or partner with a specialist AI integration services provider, the key is to start with a focused use case, validate quickly, and build with production-grade standards from the beginning.

