Introduction: The Most Important AI Decision You Will Make
When businesses move beyond simple API-based AI features and start building knowledge-intensive AI applications, they inevitably face a critical architectural decision: should they use Retrieval-Augmented Generation (RAG) or fine-tune a language model on their proprietary data?
This is not a trivial choice. It has significant implications for development cost, time to market, output quality, data privacy, and ongoing maintenance burden. Making the wrong decision can cost months of rework.
This guide explains both approaches in plain language, compares them across the dimensions that matter most to business decision-makers, and provides a practical framework for deciding which is right for your use case.
What Is Retrieval-Augmented Generation (RAG)?
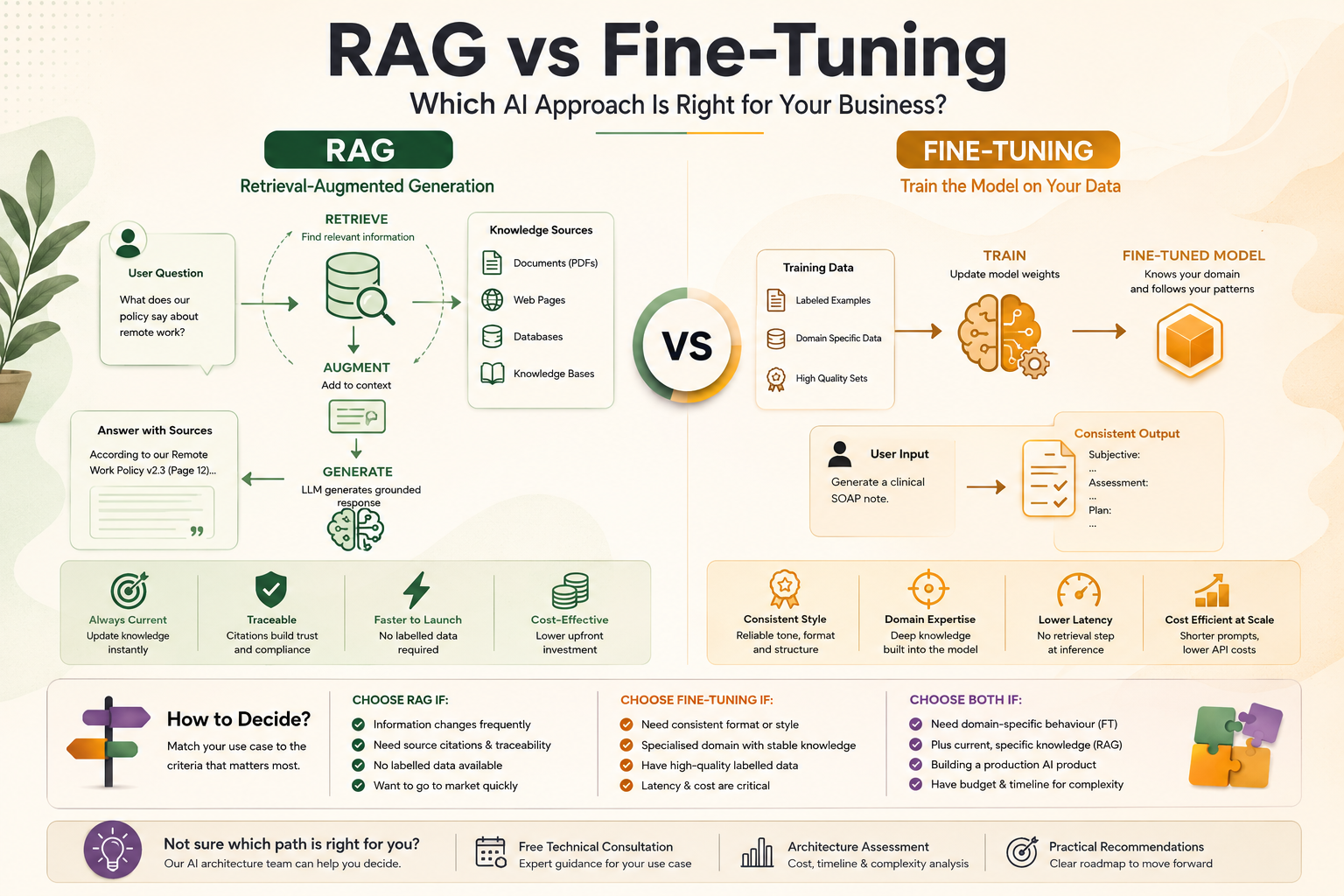
Retrieval-Augmented Generation is an AI architecture pattern that enhances a language model’s responses by giving it access to relevant external information at query time. Rather than relying solely on knowledge encoded during training, a RAG system retrieves specific, current information from a knowledge store and provides it as context to the model.
How RAG works in practice:
- Your documents (PDFs, web pages, databases, knowledge bases) are processed, chunked, and converted into numerical representations called embeddings
- These embeddings are stored in a vector database optimised for semantic similarity search
- When a user submits a query, the system retrieves the most semantically relevant document chunks from the vector database
- The retrieved content is passed to the LLM as context, along with the user’s question
- The LLM generates a response grounded in the retrieved content rather than fabricating from memory
RAG application development is the dominant approach for business applications that need to reason over proprietary, current, or confidential information — product documentation, legal contracts, financial reports, customer records, and internal knowledge bases.
What Is Fine-Tuning?
Fine-tuning is the process of taking a pre-trained base language model and continuing its training on a curated dataset of examples specific to your domain, task, or desired output style. The result is a model whose weights have been adjusted to perform your specific task better than the base model could with prompting alone.
Fine-tuning modifies the model itself, embedding domain knowledge and behavioural patterns directly into its parameters. This is different from RAG, which leaves the model unchanged and instead provides external information at inference time.
When fine-tuning makes sense:
- You need the model to consistently follow a very specific output format or structure
- You are working in a highly specialised domain with terminology and reasoning patterns not well represented in general training data
- You have hundreds or thousands of high-quality labelled examples of the task you want the model to perform
- Latency is critical and you cannot afford the retrieval step that RAG requires
- You need to reduce prompt token usage to manage API costs at high volume
RAG vs Fine-Tuning: A Direct Comparison
Knowledge Freshness
RAG wins decisively for use cases where information changes frequently. Update your vector database and the model’s responses reflect the change immediately. Fine-tuning bakes knowledge into model weights — to update that knowledge, you must re-run the fine-tuning process, which takes time and money.
Output Accuracy and Trustworthiness
For factual accuracy over proprietary data, RAG typically outperforms fine-tuning. Because the model is working from retrieved source material, its responses can be traced back to specific documents — enabling source citations and auditability. Fine-tuned models are more prone to confidently generating plausible-sounding but incorrect information when they encounter gaps in their training data.
Development Cost and Time
RAG application development has a higher initial infrastructure cost (vector database setup, embedding pipeline) but requires no labelled training data. Fine-tuning AI model services require the collection, cleaning, and labelling of training examples — a labour-intensive and expensive process. For most businesses, RAG is significantly faster and cheaper to implement initially.
Ongoing Maintenance
RAG systems require ongoing maintenance of the knowledge base — ensuring documents are current, re-embedding when content changes, and monitoring retrieval quality. Fine-tuned models require periodic re-training as your domain evolves. Both have maintenance overhead, but RAG’s is more predictable and continuous rather than periodic and intensive.
Style and Behaviour Consistency
Fine-tuning wins for use cases where you need highly consistent tone, format, or reasoning style. If you need an AI that always responds in a specific JSON schema, always uses your brand voice, or always applies a specific analytical framework, fine-tuning encodes these behaviours directly into the model in a way that prompting cannot fully replicate.
Data Privacy
Both approaches raise data privacy considerations, but differently. RAG requires your documents to pass through the LLM API at inference time — each query exposes relevant document chunks to the model provider. Fine-tuning requires your training data to be sent to the model provider during the training process. For highly sensitive data, on-premise deployment of an open-source model (Llama, Mistral) with either approach may be preferable.
Can You Use Both?
Yes — and in sophisticated AI applications, combining RAG and fine-tuning often delivers the best results. A common pattern is to fine-tune a model on your domain-specific output format and reasoning style, then augment it with RAG to ensure its responses are grounded in current, specific information.
This hybrid approach offers the consistency benefits of fine-tuning with the factual accuracy and freshness benefits of RAG. The tradeoff is significantly greater development complexity and cost.
Decision Framework: Which Approach Is Right for You?
Use the following criteria to guide your decision:
Choose RAG if:
- Your information changes frequently (product docs, pricing, policies, news)
- You need responses traceable to source documents for compliance or trust
- You do not have labelled training examples and cannot generate them at scale
- Your primary goal is making the model aware of your specific data, not changing how it reasons
- You need to go to market quickly
Choose Fine-Tuning if:
- You need highly consistent output format or style that prompting cannot reliably achieve
- You are working in a narrow, specialised domain with stable knowledge
- You have high-quality labelled training data (hundreds to thousands of examples)
- Latency is critical and retrieval adds unacceptable overhead
- You are optimising for cost at very high inference volumes where shorter prompts matter
Choose Both if:
- You need domain-specific behaviour and consistency (fine-tuning) plus access to current, specific knowledge (RAG)
- You are building a production AI product where quality is paramount
- You have the development budget and timeline for greater complexity
Real-World Examples
RAG in Practice: Enterprise Knowledge Assistant
A professional services firm integrated RAG to allow consultants to query 15 years of internal engagement reports, methodologies, and client deliverables. The system retrieves relevant historical documents and generates synthesised responses with citations — a use case where fine-tuning would be impractical (the knowledge is too vast and varied) and where accuracy and traceability are non-negotiable.
Fine-Tuning in Practice: Medical Documentation
A healthcare technology company fine-tuned a model on thousands of anonymised clinical note examples to generate structured SOAP notes in a consistent clinical format. The domain is specialised, the format requirements are rigid, and the knowledge is stable — exactly the conditions where fine-tuning outperforms RAG.
Hybrid in Practice: Legal Research Platform
A legal technology company fine-tuned a model to reason in the analytical style of a senior lawyer (applying legal frameworks, identifying risks, structuring arguments) and layered RAG on top to ground its analysis in current case law and client-specific document sets. The result is a system that reasons like a specialist and knows the specific facts.
💡 Not sure whether RAG, fine-tuning, or a hybrid approach is right for your use case? Our AI architecture team offers a free technical consultation to assess your requirements and recommend the most cost-effective path forward.
Conclusion
RAG and fine-tuning are not competing approaches — they are complementary tools that serve different purposes. RAG is the right starting point for most business AI applications: faster to implement, more accurate for knowledge-intensive tasks, and easier to keep current. Fine-tuning earns its additional cost and complexity when you need consistent behaviour, specialised reasoning, or extreme output format control.
The most important thing is to make this decision based on your specific use case requirements — not on what is technically interesting or what worked for another company. A thoughtful architecture choice at the start of your project will save significant rework and cost down the line.

