Introduction: SRE vs DevOps — Why Everyone Keeps Mixing These Up
Ask ten engineers what the difference between SRE and DevOps is, and you’ll get eleven different answers. Some will tell you SRE is just DevOps with math. Others will say they’re completely different philosophies. A few will shrug and say their company calls it DevOps but it’s basically SRE.
The confusion is real — and it has real consequences. When organizations don’t have a clear picture of what site reliability engineering (SRE) and DevOps actually mean, they end up building teams without clear mandates, shipping without proper reliability guardrails, and wondering why their on-call rotation is a nightmare.
This guide is going to give you a clear, honest breakdown of both practices — what they are, how they’re different, where they overlap, and what the right choice looks like for your engineering organization.
Not sure whether your team needs SRE, DevOps, or both? Aventis Hub’s DevOps consulting services help engineering teams build the right operational model for where they are today and where they’re going.
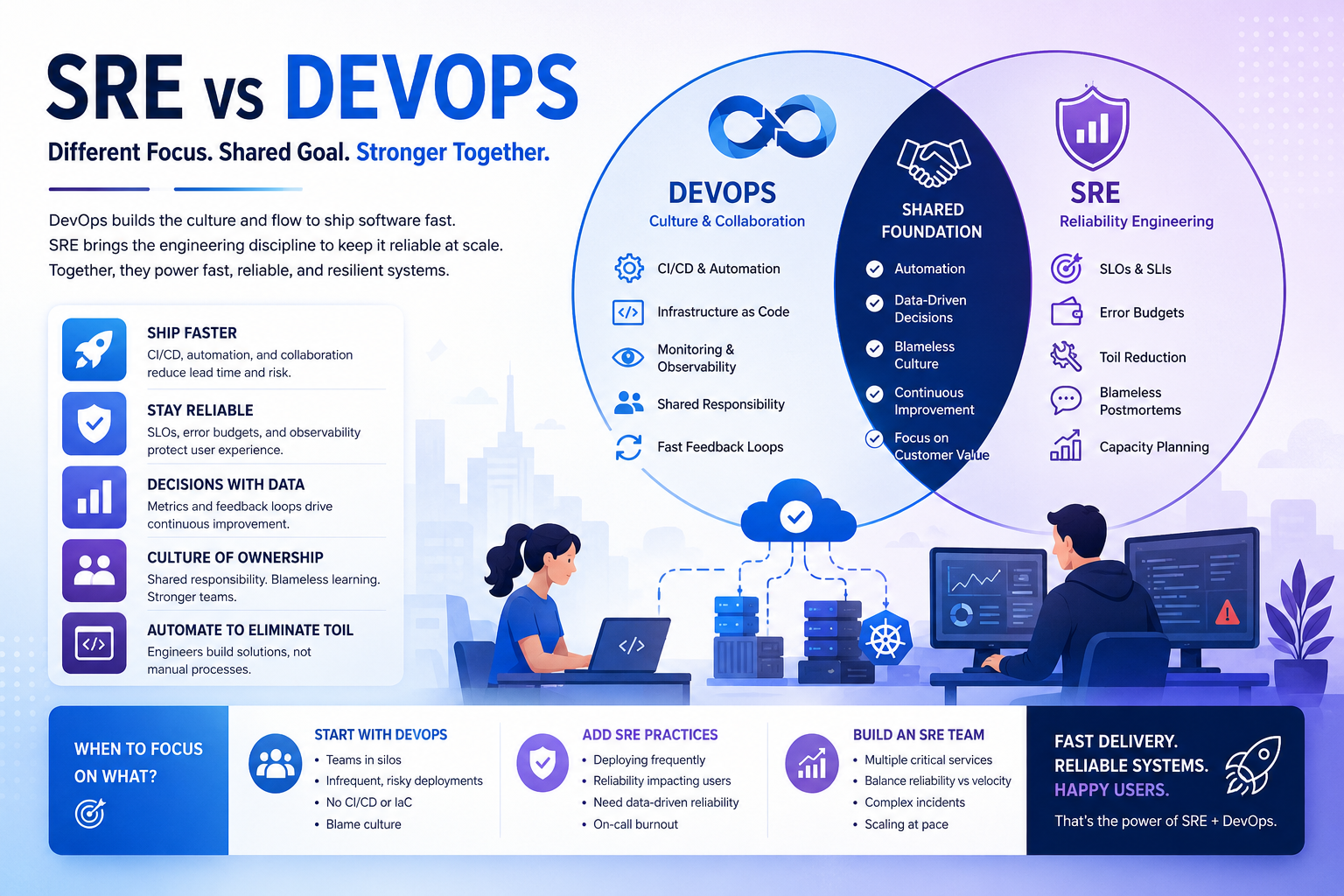
What Is DevOps? (The Non-Buzzword Version)
DevOps emerged around 2009 as a response to a very real problem: development teams and operations teams were working in silos, and it was killing software delivery speed and quality. Developers wanted to ship code fast. Operations teams wanted stability. The conflict between those goals was creating slow, painful releases and a toxic blame culture when things broke.
DevOps is a culture, philosophy, and set of practices that breaks down those silos. It encourages development and operations to work together throughout the entire software lifecycle — from design and development through deployment, monitoring, and incident response.
The core principles of DevOps include:
- Continuous Integration and Continuous Delivery (CI/CD) — automating the path from code commit to production
- Infrastructure as Code (IaC) — treating infrastructure the same way you treat application code
- Monitoring and observability — knowing what’s happening in your systems at all times
- Shared responsibility — everyone owns reliability, not just the ops team
- Fast feedback loops — catching problems early and often
DevOps is intentionally broad. It’s a culture and a mindset more than a job description. This is both its strength and its weakness — it means different things at different organizations, which can make it hard to implement consistently.
Learn more about DevOps fundamentals from the DevOps Institute or explore Google’s DevOps research through DORA.
What Is Site Reliability Engineering (SRE)?
Site Reliability Engineering was invented at Google around 2003 by Benjamin Treynor Sloss, and it started with a simple premise: hire software engineers to do what used to be done by operations teams.
The fundamental insight behind SRE is that operations problems are fundamentally software problems. If your infrastructure is fragile, you don’t just need better processes — you need better software, better automation, and better systems thinking.
SRE is more prescriptive than DevOps. It comes with a specific set of practices, metrics, and engineering principles:
- Service Level Objectives (SLOs) — concrete, measurable targets for how reliable a service needs to be (e.g., 99.9% uptime)
- Service Level Indicators (SLIs) — the actual metrics you measure to assess reliability (e.g., latency, error rate, availability)
- Error Budgets — the acceptable amount of unreliability. If your SLO is 99.9% uptime, your error budget is 0.1% — and it can be spent on risky deployments or absorbed by incidents
- Toil reduction — systematically eliminating repetitive, manual operational work through automation
- Blameless postmortems — post-incident reviews focused on system improvement, not individual blame
- Capacity planning — proactively planning for scale before it becomes a crisis
Google’s SRE books — available free online — are the foundational texts for anyone serious about reliability engineering.
SRE vs DevOps: The Core Differences
Now that we understand both, let’s put them side by side.
1. Philosophy vs Practice
DevOps is primarily a cultural philosophy. It says: “Development and operations should work together, share responsibility, and communicate openly.” It’s a set of values and principles that can be implemented in many different ways.
SRE is a specific implementation of reliability engineering principles. It says: “Here’s how you quantify reliability, here’s how you balance reliability and velocity using error budgets, and here’s how you structure the team to make it happen.”
In fact, Google’s SRE handbook makes this relationship explicit: “SRE is what happens when you ask a software engineer to design an operations team.”
2. Scope
DevOps covers the entire software delivery lifecycle — from how developers write code to how it gets deployed to how it’s monitored in production. The scope is broad by design.
SRE is specifically focused on reliability and operational excellence in production. It cares deeply about how services behave under load, how incidents are managed, and how reliability is measured and maintained over time.
3. Metrics and Measurement
DevOps success is often measured with deployment frequency, lead time for changes, mean time to recovery (MTTR), and change failure rate — the DORA metrics.
SRE success is measured with SLOs, error budgets, and toil reduction. These are more specific and more directly tied to user experience and business outcomes.
4. Team Structure
In a DevOps culture, there may not be a dedicated “DevOps team” — the goal is for everyone to share operational responsibility. DevOps engineers often sit within product teams or a platform team, providing tooling and pipelines.
In a mature SRE model, there’s typically a dedicated SRE team (or embedded SREs within large product teams) with specific responsibility for reliability. They have the authority to slow down deployments if reliability is at risk — enforced via error budget policies.
5. How They Handle Toil
DevOps acknowledges that manual operational work is bad and automation is good. SRE goes further: it quantifies toil and typically limits SRE engineers to spending no more than 50% of their time on operational work. The rest goes to engineering projects that reduce future toil.
Where SRE and DevOps Overlap
Despite the differences, SRE and DevOps aren’t in competition — they’re deeply complementary.
Both share a commitment to:
- Automation over manual processes
- Reducing silos between developers and operations
- Using data and metrics to drive decisions
- Continuous improvement through feedback loops
- Blameless culture around incidents and failures
Many organizations practice both simultaneously. DevOps principles govern how teams collaborate and ship code, while SRE practices govern how production reliability is managed and measured. This is actually the most common and effective model at scale.
Want to build a DevOps culture that also has real reliability engineering discipline? Aventis Hub’s SRE consulting services help teams build the organizational model and tooling they need to scale confidently.
What Is Platform Engineering — and Where Does It Fit?
You might have noticed a third term showing up more frequently in 2024 and 2025: platform engineering. It’s worth a quick mention here because it often gets conflated with both SRE and DevOps.
Platform engineering is the practice of building and maintaining internal developer platforms (IDPs) — the golden paths, self-service tooling, and standardized infrastructure that product teams use to deploy and operate their services.
Think of it this way:
- DevOps is about culture and collaboration
- SRE is about measuring and engineering reliability
- Platform engineering is about building the internal products that make developers productive and operations consistent
All three can and often do coexist in mature engineering organizations. The CNCF Platforms White Paper is a great resource if you want to go deeper on platform engineering. Our platform engineering services can help you build internal platforms that reduce cognitive load on your development teams.
Which One Does Your Organization Actually Need?
Here’s a practical framework for figuring out what makes sense for where you are:
You probably need DevOps fundamentals first if:
- Your development and operations teams are still working in silos
- Deployments are infrequent, risky, and stressful
- You don’t have a CI/CD pipeline or it’s inconsistently used
- Infrastructure is managed manually without version control
- There’s a blame culture around incidents
You’re ready for SRE practices if:
- You’re deploying frequently and reliability is becoming a real concern
- Users are experiencing production incidents that hurt retention or revenue
- You want to have data-driven conversations about how much reliability you can afford
- Your on-call rotation is unsustainable and engineers are burning out
- You’re scaling to the point where informal reliability practices no longer work
You might benefit from a dedicated SRE team if:
- You’re running multiple critical services with different reliability requirements
- You need to balance feature velocity with reliability in a structured, measurable way
- Incidents are becoming more frequent and more complex to resolve
A useful rule of thumb: most companies should establish DevOps culture and CI/CD practices first, then layer in SRE disciplines as their services and scale demand it.
Real-World Examples: How Companies Apply Both
Netflix
Netflix is famous for its Chaos Engineering practices — deliberately breaking things in production to build more resilient systems. This is SRE discipline applied at enormous scale, built on top of a strong DevOps culture.
The originators of SRE, Google uses both rigorously. Their SRE practices are documented in the Google SRE Book — required reading for anyone serious about reliability.
Smaller Teams
Startups and growing engineering teams often start with DevOps practices (CI/CD, IaC, monitoring), then introduce SRE concepts like SLOs and error budgets as they scale. You don’t need a 10-person SRE team to define SLOs — a single SRE-minded engineer can make a huge impact.
Common Misconceptions About SRE vs DevOps
“SRE is just a fancier name for DevOps” — Not quite. SRE is a specific, prescriptive implementation with its own vocabulary, metrics, and principles. DevOps is a broader cultural philosophy.
“You have to choose one or the other” — Not true. Most mature organizations practice both. DevOps governs delivery culture; SRE governs reliability engineering.
“SRE is only for big tech companies” — False. Error budgets, SLOs, and blameless postmortems are valuable at any scale. Even a 10-person startup can benefit from defining what “reliable enough” means for their services.
“DevOps means you don’t need operations people” — A persistent and damaging myth. DevOps is about collaboration, not elimination. You still need people who specialize in infrastructure, reliability, and operational excellence.
The Bottom Line: SRE vs DevOps
DevOps gives you the culture, practices, and tooling to ship software faster and more reliably — breaking down silos and enabling continuous delivery.
SRE gives you the engineering discipline, metrics, and team structure to manage reliability at scale — measuring how reliable your services are and making data-driven decisions about where to invest.
They’re not competitors. They’re complementary. The best engineering organizations practice both — and they do it intentionally, with the right people and the right tooling in place.
Build the Right Engineering Model for Your Team
Whether you’re just starting your DevOps journey, scaling into SRE practices, or trying to untangle years of operational complexity, having the right guidance makes the difference between a transformation that sticks and one that doesn’t.
Aventis Hub offers SRE consulting, DevOps consulting, and platform engineering services for teams at every stage of maturity.
👉 Get in touch with our team and let’s build the operational foundation your organization actually needs.
Further reading:

